There is a standard phrase about movies that were made after books. “The book was better”. [Some people are rather annoyed by this](http://www.garry.tv/?p=398), because you always hear it that way, never any other. But what can I do when seeing a movie where the book is really better, such as “[The Golden Compass](http://www.goldencompassmovie.com)”?
Dear [Mr Gruber](http://daringfireball.net/2007/12/fastcompany): I know you are doing this stupidly long title not because you don’t know how to make short ones, but rather because you think it’s funny to have such a long title. Also, you put some of the basic points raised against articles like that right in the title, to show how serious you are about them. So in a sense, it cannot be too long. However, when NetNewsWire truncates the title while showingit, then I think it’s save to say something is wrong.
My mother just pointed out to me that the pictures I posted show a definite lack of Alfa Romeo. To a certain degree, this is due to this Meilenwerk, which just does not have all that many Alfas and seems to focus more on Great Britain. However, there were some, and I agree, it was bad of me not to post them. So here they are.
I spent the day at the [Meilenwerk Düsseldorf](http://www.meilenwerk.de/). This place describes itself as “Forum für Fahrkultur”, which can be translated as “Forum for driving culture”. It is an area for all things that have to do with exclusive cars, including stores, repair shops, insurance salesmen, a restaurant and lots of place to store your exclusive cars, should you have any. There are currently two of these, on in Berlin and one in Düsseldorf. A third one will open in Stuttgart soon.
In the end things worked out sooner than I thought they would, so I can now offer you Hubschrauber 3 for download!
I’m planning to release a new version of [Hubschrauber](/en/software/hubschrauber) later this weekend. You’ll hear more details, such as contents and why this half-year delay, as we get closer to the launch. For now, there is just one important question going through my mind:
You may or may not have noticed that I recently changed lots of stuff on my homepage. I wouldn’t be suprised if you hadn’t, because the only style change I made was to change the look of my comment field. But there is more!
I’m currently posting about this on all sites I have a password to, so my own homepage should probably recieve the information as well:
As a direct follow-up to my [previous post](/en/blog/2007/11/Informatiklehrer), some more observations. Seems like it is common to discourage something because it’s “bad style”. As an example, accessing static class attributes using an instance instead of using the class object.
Only german
Erst mal ein Hinweis: Ich bin gerade bei größeren Umbauarbeiten, weil ich die Seite auf ein stabileres System umstellen will, wie ich es schon für [TrainsInGames.com][tig] getan habe. Die statischen Seiten ([Software][soft], [Comics][com]) sind schon fertig, aber der News-Bereich wird noch stark bearbeitet werden. Wie immer werden alle alten Links auch weiterhin funktionieren.
Only german
Ich habe an diesem Samstag die [Maclive Expo](http://www.macliveexpo.de/) in Köln besucht. Die Wegweiser waren nicht ganz auf dem selben Standard wie die zur IAA, aber ich habe den Weg trotzdem gefunden.
Only german
Die Privatisierung der DB-AG war schon lange Zeit kipplig, aber jetzt scheint man sich endlich dagegen entschieden zu haben. Die SPD will eine Volksaktie ohne Stimmrecht, die CDU lehnt das strikt ab und Tiefensee schließt daraus, dass das wohl nichts mehr wird. Quelle: http://www.heute.de/ZDFheute/inhalt/2/0,3672,7118178,00.html
Only german
Mein Plan war die ganze Zeit, diesen Post genau heute zu schreiben, ab dem Zeitpunkt, ab dem es [Valve’s](http://valvesoftware.com/) [Orange Box](http://orange.half-life2.com/) auch in Deutschland in Läden zu kaufen gibt. Natürlich stelle ich heute fest, dass dies eigentlich schon gestern der Fall war. Scheisse.
Only german
Ich will nicht ganz ausschließen, dass ein paar Leute gerade heute sich erstmals ansehen, was Ferroequinologist.de eigentlich ist, da ich die Adresse ein wenig verteilt habe. Klar, es ist unwahrscheinlich, aber man soll ja niemals nie sagen. Was ist es nun also? Ganz einfach, es ist meine private Homepage, und ich selbst bin Torsten Kammer, seit gestern Informatikstudent an der RWTH Aachen.
Only german
Seit zwei Tagen (ich habe per Steam gekauft) spiele ich jetzt die Spiele von Valve’s Orange Box, und ich muss sagen, die Dinger sind echt genial. HL2 Episode Two ist verdammt cool, und Portal ist sowieso das beste, was es gibt. Sehr lustig finde ich auch die Idee der Achievements, die es hier gibt. Man kann sich streiten, ob die Menschheit so etwas wirklich braucht, aber es ist auf jeden Fall lustig, dafür belohnt zu werden, möglichst viele Kameras abzureißen.
Only german
So, seit Dienstag wohne ich in Aachen, da ich demnächst beginnen werde, hier Informatik zu studieren. Daher habe ich eine neue Telefonnummer (die noch nicht freigeschaltet ist) und eine neue Adresse. Wer eins von beiden oder beides braucht, fragt mich einfach!
Only german
Die Deutsche Bahn AG hat derzeit zwei große Krisen. Eine ist der Tarifkonflikt mit der Gewerkschaft der Lokführer, in dem es auch gerade wieder einen Rückschlag gab. Die andere ist die geplante Privatisierung, die in der öffentlichen Meinung derzeit in alle Einzelteile zerissen wird. Insbesondere im Hinblick auf letzeres ist es interessant zu beobachten, wie der Konzern auf die durchgängig negative Presse reagiert.
Only german
Heute war ich auf der IAA in Frankfurt am Main. Manch einer mag denken, dass diese erst am Donnerstag beginnt. Das stimmt vielleicht für das Fußvolk, aber heute und morgen sind reserviert für akkreditierte Pressevertreter, was das Gedränge geringfügig erträglicher macht. Nicht, dass es an Gedränge gemangelt hätte:
Only german
Inzwischen bin ich etwas spät dran, und dass, obwohl ich das Buch in der Launch-Nacht um 0:00 (ehrlich gesagt eher 0:30, die Schlange war laaaaaang) britischer Zeit gekauft habe. Das hätte ich übrigens nicht getan wenn meine Schwester nicht darauf bestanden hätte, ihres schon so verdammt früh zu kaufen, aber das ist jetzt auch nicht so wichtig. Auf jeden Fall war ich lange in Schottland und hatte so keine Gelegenheit, diese Homepage zu aktualisieren.
Only german
Übermorgen erscheint Harry Potter And The Deathly Hallows, das letzte Buch der berühmten Serie, offiziell auf Englisch. Ich bin zu diesem Zeitpunkt in Schottland und kann darum auf dieser Homepage relativ wenig dazu sagen. Daher möchte ich jetzt schon mal die Gelegenheit nutzen, meine persönlichen Theorien für Buch 7 bekannt zu geben. Hinterher vergleiche ich diese dann mit der Realität. Wird sicher lustig.
Only german
Es hat sich eine Menge Kram ergeben, den ich hier noch nicht erwähnt habe, der aber trotzdem erwähnenswert ist. Also, in keiner bestimmten Reihenfolge:
Björn is in the army now. That is, of course, completely irrelevant. However, he mentions, deep in the bowels of the article, that he wants to update his homepage. I cannot let that happen without action, so I have to update mine first.
My model railroad (which I didn’t talk about enough here) is completely digitally controlled. That means the locomotives aren’t controlled by the height of the track voltage. Instead, they are connected via the rails to a network, which I can use to give specific commands to every single engine. That way, I can control them completely individually.
Only german
Kurzer Hinweis: Safari 3 für Windows kann fette und kursive Schriften nur im Ausnahmefall (genauer: Wenn eine spezielle fette oder kursive Version der Schrift existiert) korrekt darstellen. Das macht den Browser für den allergrößten Teil des Webs unbrauchbar. Wer sich dafür interessiert: Downloadet den Browser noch nicht, sondernd wartet auf die nächste Version der Beta. Ansonsten werdet ihr ihn frustriert in eine Ecke werfen und nie wieder ansehen, was sehr schade wäre.
Only german
Dieses Wochenende war mal wieder eine LAN bei Björn. Schöne Sache. Dabei habe ich auch mal wieder eine neue Version von Hubschrauber verteilt, die sich prompt als unbrauchbar herausstellte. Inzwischen habe ich aber schon einige der schlimmsten Bugs behoben, und wenn ich den Rest der Bugs auch noch gekillt habe (derzeit kann bei einem Mehrspielerspiel nur der Server seinen Hubschrauber steuern), dann werde ich darüber nachdenken, wieder eine neue Version zum Download anzubieten.
I’ve been meaning to post this since sunday, but I never got around to it: I’ve made a new Tomb Raider Comic. The title is Point of View. I’ve had this idea for some time, but TR Poser doesn’t have the features to do it as I originally planned. In the end, I decided to make it (but much shorter) because I just liked the general idea. I hope you enjoy it.
Only german
Wie angekündigt, habe ich den gestrigen Tag damit verbracht, Reflektionen zu Hubschrauber hinzuzufügen. Nebenbei habe ich auch noch zwei weitere Hubschrauber eingebaut, die ich wohl irgend wann vergessen hatte. (Noch zwei weitere liegen ebenfalls auf der Festplatte. Diese haben aber ein Einziehfahrwerk und benötigen darum mehr Code, bevor sie kommen können).
Only german
Diese Woche hatte ich (und nächste habe ich auch noch) Urlaub. Dabei haben sich verschiedene Sachen ergeben, die alle nicht wichtig genug waren, um einzeln angesprochen zu werden, aber in der Summe doch ganz interessant sind.
This weekend, there is a LAN over at Eidi’s place. If you don’t know who Eidi is, then never mind, as you won’t be invited anyway. Said LAN has caused me to change all my plans for the future roadmap. I plan to release 2.1 this weekend, at this LAN.
Now Hubschrauber Release 2 or whatever you call it is out. If you don’t have it yet, you should get it, like soon. So, what am I going to do now?
It took a lot of time and work, but it’s finally done. Hubschrauber Alpha 2 is finished and you can download it.
Hubschrauber Release 2 is done. Nearly. It works fine on Mac OS X, and it works well on Windows 2000, too. The problem is on the more modern versions of Windows.
Only german
Meine Damen und Herren, hier der letzte Punkt auf meiner Liste: Halbwegs anständige Fehlermeldungen:
I have the problem that my hands start to sweat when playing video games. For this reason I bought a Logitech ChillStream gamepad yesterday. That is a gamepad with a built-in fan to cool the hands. Sounds silly on the very first thought, but it’s actually a neat idea.
Only german
Mein neuestes gelöstes Problem ist das Problem, dass die Welt ein Ende hatte, eine sehr scharfe Kante, wo man runter fallen konnte. Dies ist jetzt endlich nicht mehr der Fall.
For a game dealing with flying, Hubschrauber has had an awful crappy sky so far. This has changed now. Thanks to the use of a skybox, the sky now looks like sky should:
Only german
Ich schraube immer weiter an Hubschrauber, und habe jetzt ein weiteres, wichtiges Feature eingebaut: Verschiedene Maps.
Only german
Meine Güte, ich habe mal wieder lange nichts über Hubschrauber geschrieben. Hier also die neueste Neuigkeit: Man kann sich jetzt einen von mehreren Hubschraubern aussuchen.
Only german
Wie mir gerade aufgefallen ist, habe ich hier nie gepostet, dass ich derzeit Zivildienst mache. Tut mir leid, ist wohl irgendwie untergegangen. Also: Seit dem 15.10.2006 leiste ich meinen Zivildienst in Bad Harzburg im Wichernhaus (ein Altenheim). Mit ein bisschen Mathe kommt man schnell darauf, dass ich heute genau die Hälfte der neun Monate hinter mir habe.
Only german
In den USA gab es vor kurzem einen bestürzenden Fall: Ein paar Jugendliche haben zum Spaß einen Obdachlosen getötet. Wichtig hieran ist: Einer von ihnen hat gesagt, dass dies ungefähr damit vergleichbar sei, ein gewalttätiges Computerspiel zu spielen. Klarer Fall also für Politiker weltweit: “Killerspiele” gehören verboten
Only german
Hier eine kleine Benutzeranleitung für Hubschrauber, um Fragen zu beantworten, die ich immer wieder erhalte.
There was a competition in the official Eidos Community Forums to create some fan art concerning Lara Croft’s Birthday. The deadline for submission is through, but judging isn’t finished (maybe it hasn’t even started) yet. I thought I’d post my entry here, in case anyone is interested.
Hubschrauber didn’t run on Windows Vista until now. That just changed. Not because of anything I’ve done, but because ATI finally released OpenGL drivers.
And again, I’ve finished the Mac version enough for the release at Björn’s LAN this friday. By the way, this version will be only available at Björn’s LAN, so if you aren’t invited, sorry, bad luck. Anyway, I now started porting everything to Windows.
Björn Gernert,a good friend of mine and also my hosting provider, has his birthday today. Congratulations, Björn!
I’ve implemented the new file format I talked about in Hubschrauber. There are still some things I want tweaked in the Mac version, but soon, I’ll start and bring the Windows version up to speed. To make this post less boring, here a screenshot:
Only german
Ich möchte hiermit ganz herzlich all die jenigen auf meiner Homepage begrüßen, die mich vom Lehrgang in Rastede kennen. Extra für euch habe ich jetzt in meinem Software-Bereich auch etwas über Hubschrauber geschrieben. Komplett mit Screenshots und allem. Hinterlasst bitte dort unten einen Kommentar, das finde ich immer ganz muckelig.
Sorry, no screenshots. I was too lazy.
Only german
Zu Weihnachten habe ich ein neues Spiel bekommen: LEGO Star Wars I in der Mac-Version.
Some time ago I wrote something about Dreamfall. My main conclusion was: Cool story, not much game, definitely worth it’s money. I only now noticed that there is a demo available. Theoretically, I’d recommend you to go, download and play it, but practically, it weighs 3.5 GB, so you might want to think twice about it. I guess it’s the full game with a time limit.

 Deutsche Version
Deutsche Version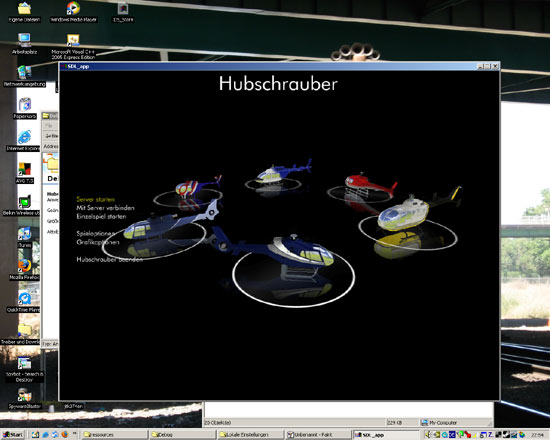
{kind=link}
{kind=link}
{kind=link}
{kind=link}